
.png)

Most of the businesses have shifted toward automation tools and AI automation solutions, not because it's trendy, but because the alternative stopped working. Manual work was slowing teams down, core processes struggled to handle growing workloads, and customer expectations kept increasing. Organizations that got AI Agents right saw faster lead response times and stronger customer service almost immediately.
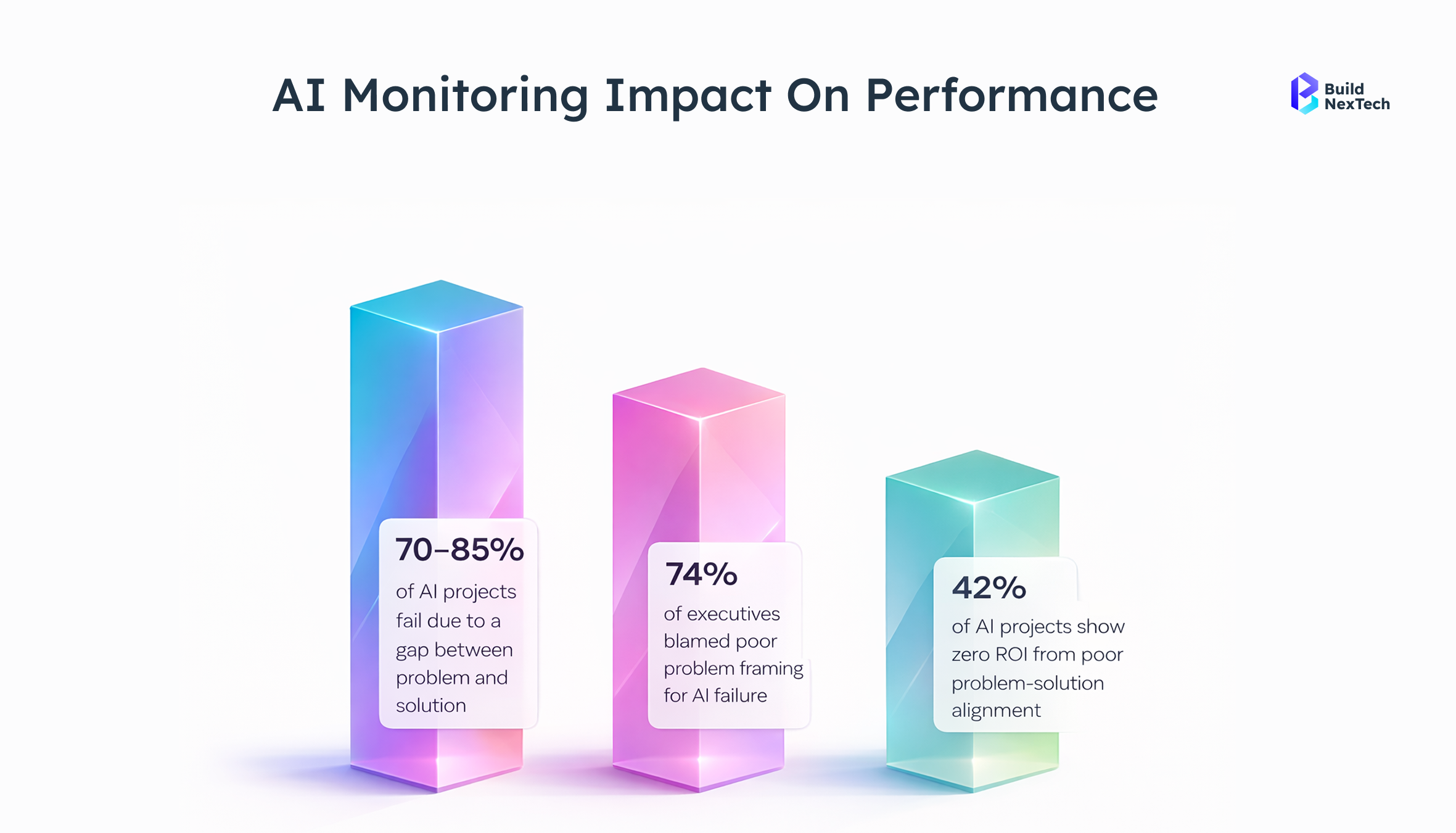
But most didn't get it right. Industry studies show 95% of AI projects never deliver meaningful business outcomes. The technology rarely fails on its own; what fails is the execution around it. Rushed rollouts, overlooked data quality, insufficient human oversight, and no real strategic plan quietly turn promising investments into costly liabilities.
This article covers the most common automation mistakes driving hidden costs, and what fixing them actually looks like, so your investment moves toward genuine returns and lasting human-AI collaboration.
Critical AI Automation Mistakes and Failure Points
Most AI automation failures trace back to four repeating execution gaps, not technology limitations. Poor planning, absent monitoring, and weak integration are what consistently derail even well-funded deployments. The downstream effects are consistent: rising costs, shrinking efficiency, and an ROI that no longer justifies the investment.
When these compounds are combined, the result is predictable: rising costs, reduced efficiency, and an ROI that no longer justifies the spend.
Poor Data Quality and Data Drift Issues
Most AI automation projects don't fail at launch; they fail weeks earlier, when someone decides the data was "good enough." Incomplete training data, datasets stitched together from multiple automation tools, no real data quality analysis in place, the predictive models built on top of that foundation were never going to hold up.
And when the AI model runs on a static algorithm that nobody revisits, real-world drift isn't a risk. It's a guarantee. Nearly 49% of executives now flag data inaccuracies as their biggest barrier to AI-powered automation and you can see why. Inaccurate shift data once caused an AI scheduling tool across 6,000+ stores to collapse so badly that managers manually overrode 84% of its outputs.
- Disconnected systems delivering inconsistent inputs → data fragmentation that corrupts model logic from the start
- Over-reliance on manual data entry → duplicate records, compounding errors that quietly grow
- No data anonymization protocols → real exposure to data leaks and privacy violations
- Careless handling of confidential data → a security risk that builds at every pipeline stage
Lack of Continuous Monitoring and Feedback Loops
Deployment isn't the finish line; it's where accountability starts. Without real-time monitoring systems, model drift builds unnoticed. Customer satisfaction takes hits before anyone flags a problem, and by the time workflow efficiency shows cracks, weeks of compounding errors have already done damage. Every missed retraining window is a window where errors multiply. KPI reporting exists to prevent this, but only when it's measuring what actually matters.
- Real-time monitoring systems detect accuracy drops from 92% to below 85%, triggering retraining of predictive models before damage compounds
- KPI reporting ties the automation plan to business outcomes, not just technical uptime
Weak Integration and System Design Limitations
The AI tool gets built, testing passes, production hits, and API integration gaps surface immediately. API mismatches cause data handoff failures. Pipelines with no error handling drop records silently. Sloppy workflow mapping breaks previously functioning processes, pushing teams back into manual data entry. Weak system design opens up data leaks, privacy gaps, missing role-based access control, and no audit logs. None of that is cheap to fix retroactively.
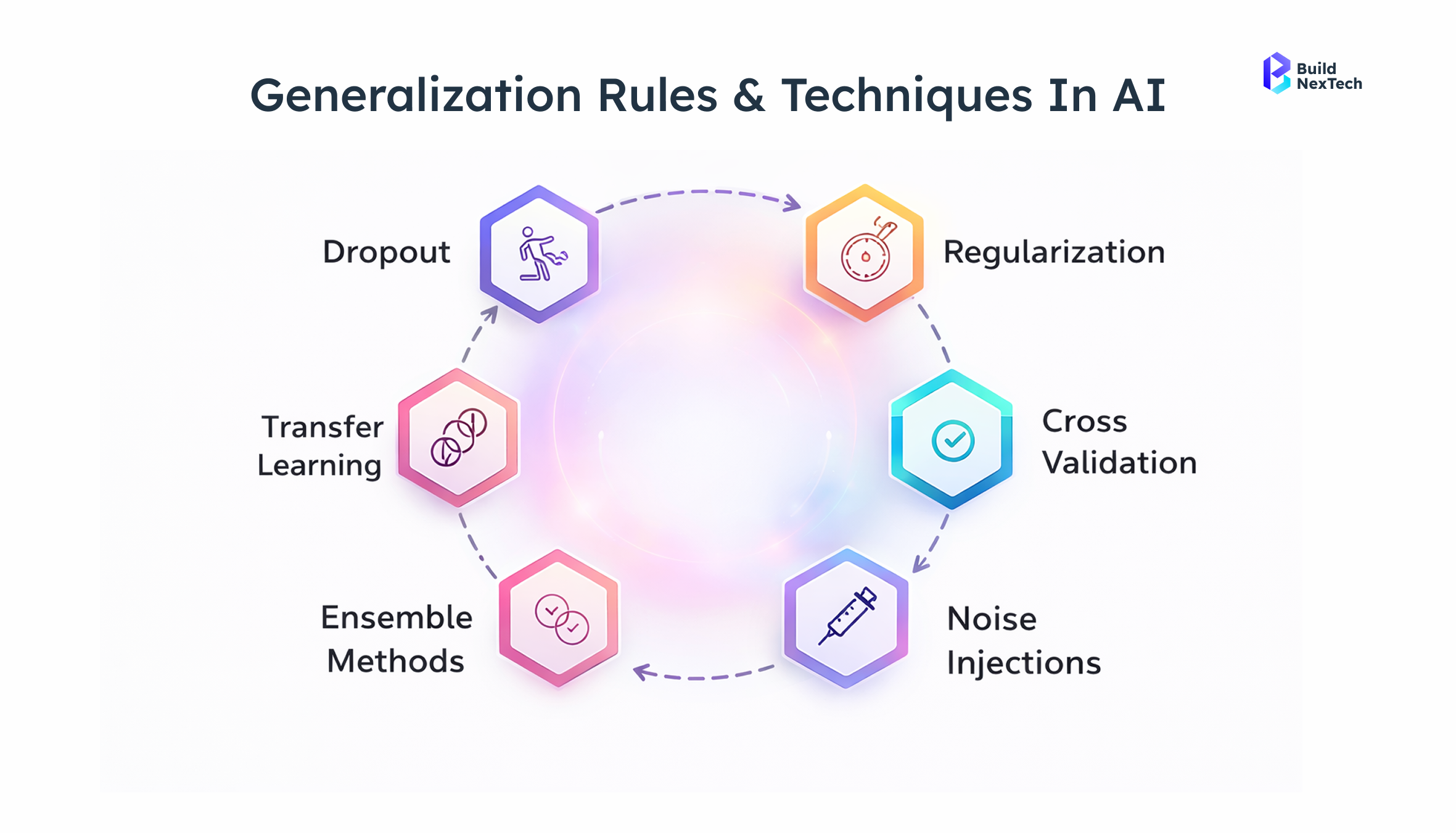
Overfitting and Poor Model Generalization
An artificial intelligence model that aces testing can completely fall apart in production. It happens when teams train model systems on narrow datasets without proper data quality standards, the model memorizes the training set instead of learning the actual problem.
- Performs well on training data, breaks down when real users show up
- Missing KPI reports keep performance gaps hidden for weeks
- Weak training programs leave the model unable to adapt
For example, A fintech company's fraud detection artificial intelligence model hit 94% accuracy in testing. In production, newer fraud patterns emerged that it had never seen within 90 days, over 200 transactions were missed. Proper AI model training validation would have caught the drift.
Ignoring Edge Cases in Real-World Scenarios
Neural networks trained in controlled environments struggle with what real-world use actually throws at them. In communications, media, and technology (CMT) sectors, unexpected inputs trigger AI hallucination, confident but completely wrong outputs affecting real decisions. A customer service AI model hallucinating product details or policy information causes direct business damage.
Strong AI infrastructure, regular compliance reviews, and a human-first mindset are what keep edge case failures from quietly destroying customer trust.
How to Fix AI Automation Failures:
Most AI automation fixes don't require a full rebuild. They require addressing the right problems in the right order, starting with data quality, moving through monitoring and evaluation, and finishing with alignment to real business development outcomes. Here's what that looks like in practice.
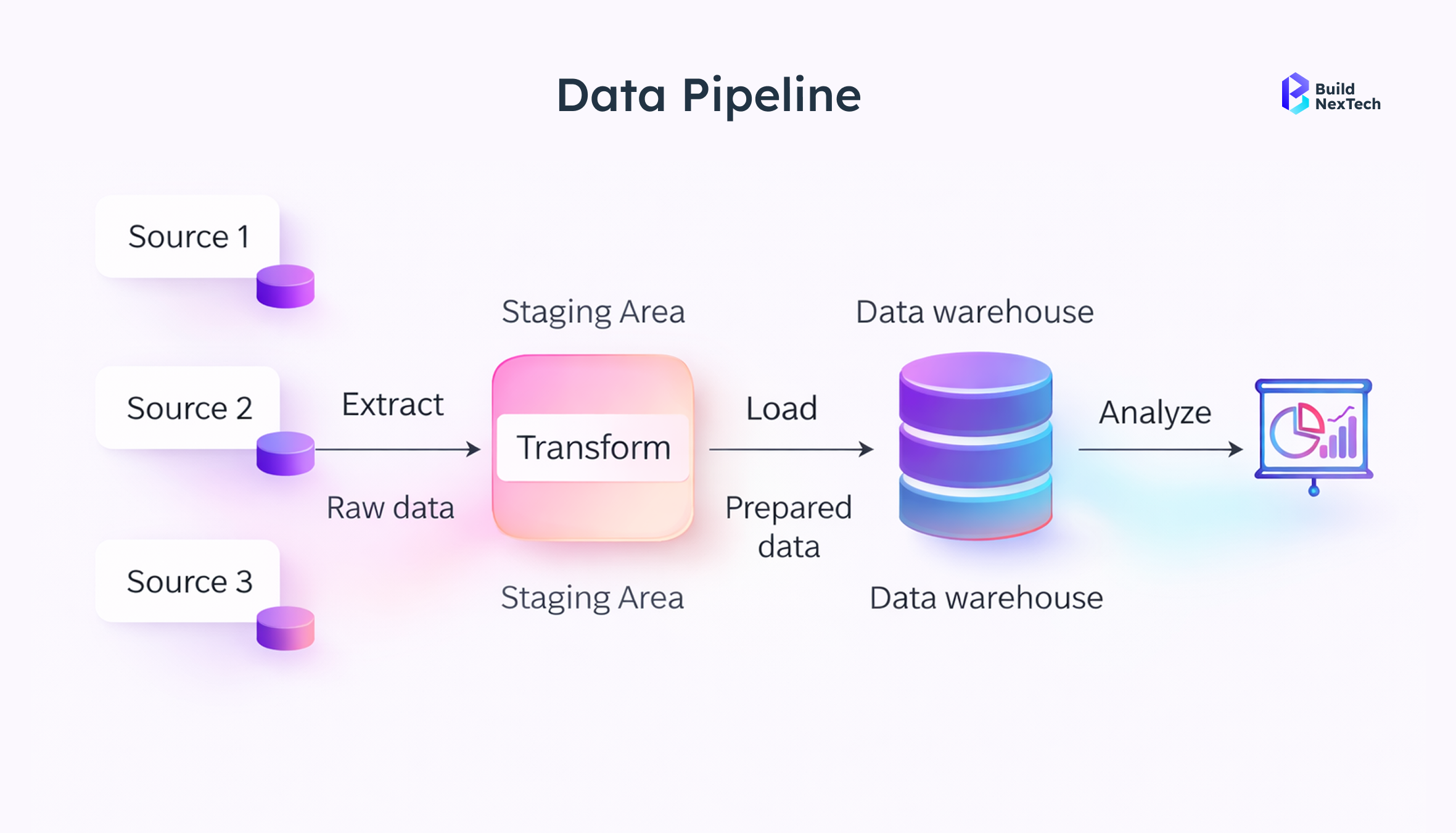
Build Reliable Data Pipelines
AI learning models are only as reliable as the data feeding them. Poor data quality, data fragmentation, and excessive manual data entry corrupt outputs before the model ever reaches production.
ETL (Extract, Transform, Load) frameworks with schema validation, duplicate detection, and null-value handling catch inconsistencies at the source. Great Expectations and Apache Griffin enforce data quality standards at the pipeline level, not just at setup, but continuously throughout model development.
- Validate at both input and processing stages, schema checks, type enforcement, range validation
- Automated deduplication catches compounding errors before they reach the AI model
- Consistent dataset formatting across all sources is what automation solutions depend on
Implement Continuous Monitoring and Alerting
Degradation doesn't announce itself. Without structured monitoring and evaluation, AI model performance slips quietly, even in environments running on Cloud Computing infrastructure.
Prometheus handles metrics collection. Grafana visualizes performance trends. Evidently, AI specializes in model drift detection, flagging when real-world data distribution shifts away from training data. Together, these tools give teams architecture-level visibility rather than relying on manual spot checks.
- Real-time KPI reporting tracks accuracy, latency, and error rates, not just uptime
- Threshold-based alerts trigger retraining workflows when accuracy drops beyond defined limits
- Scheduled revalidation cycles catch gradual drift before it compounds into visible failures
Use Version Control for Models and Datasets
Without version control, a failing AI model is nearly impossible to debug. Teams can't identify what changed, when it changed, or which dataset version caused the performance drop.
MLflow tracks experiment runs, model versions, and performance metrics in one place. DVC (Data Version Control) links specific data versions to the models trained on them. A logistics company using DVC caught an upstream schema change that had silently corrupted three weeks of predictions; the rollback took under an hour. Without version control, that investigation would have taken weeks. Nearly 80% of artificial intelligence models never clear the experimental stage; version control is one of the simplest ways to change that.
- Full change tracking across models and datasets with linked version histories
- Clear commit history showing what changed between every model version
- Roll back to previous stable versions without rebuilding from scratch
Design Scalable AI Workflows (Not One-Off Models)
Single-use AI workflow automation is technical debt with a timer on it. A model built for one team and one task works until requirements shift and the whole thing needs rebuilding.
Scalable architecture means event-driven design using message queues like Apache Kafka for async processing, modular pipeline components that update independently, and API-first integration patterns connecting systems across departments without hard dependencies. Proper workflow mapping before build prevents the bottlenecks that kill scaling later. Solid AI infrastructure absorbs requirement changes without requiring full reconstruction.
- Modular pipeline components are updated independently without rebuilding the entire system
- API-first integration connects cross-department systems without creating hard dependencies
- AI infrastructure capacity-planned for growth, not just current load
Align AI Systems with Business Outcomes
An AI automation system that nobody can tie to a measurable result gets cut. Low ROI and poor adoption trace back to one consistent problem: systems built around technical specifications rather than actual business needs.
KPIs defined before deployment give teams a clear benchmark. Real examples that move decisions: cost-per-transaction reduction from $4.20 to $1.80 through automated processing, fraud detection rate improvement from 67% to 89% after AI model training refinement, and customer satisfaction score increase of 14 points following AI workflow automation of support routing. These numbers make AI automation software investment defensible and drive genuine ROI optimization.
Change management paired with structured onboarding builds the employee buy-in that determines whether automation solutions actually get used.
- Define KPI reports covering processing time, error rates, cost-per-transaction, and revenue impact
- Connect every AI automation output directly to a measurable business objective
- Build adoption through structured onboarding, not assumption
Conclusion: Creating Scalable AI Automation
The success of AI automation relies on proper implementation. Data quality, efficient API, and scalability need to be considered in building such systems. The trend shows that more companies are using a private AI model approach, while the use of entity recognition is increasing to increase accuracy in applications.
As mentioned in the WEF 2023 Report, one needs to ensure that the interaction between AI and humans is good enough to get success from it. In this regard, it is important to focus on the relationship-based touchpoints along with emotional resilience.
- Maintain good quality data by ensuring continuous monitoring
- Make sure to optimize the usage of the API
- Apply the private AI model concept for more control
- Employ entity recognition to enhance accuracy and automation
- Concentrate on human interaction and make
How BNXT Helps Businesses Avoid AI Automation Failures
A vast majority of AI mishaps happen as a result of poor implementation, such as unclear workflow, inconsistent data, and absence of monitoring. At BNXT, our main aim is to address these weaknesses through the creation of robust AI solutions which are built to be implemented in the real world environment of your company.
- Design of AI workflow: Alignment with your business processes
- Creation of data pipelines: Consistency of your data
- Monitoring systems for AI models: Detection of problems before they occur
- ROI optimization: Linking of your AI performance to your business needs
This approach helps businesses avoid common AI failures and achieve consistent results.
People Also Ask

1. What are AI automation mistakes?
AI automation mistakes are gaps in data, planning, or execution that reduce the performance of an AI model. They often lead to wrong outputs, misclassification, and poor decision-making in enterprise systems.
2. What are the most common AI automation mistakes?
Common mistakes include poor data quality, weak Data Privacy, broken API calls, lack of monitoring, and repeated duplicate actions. These issues affect how machine learning and neural networks perform.
3. Why do AI automation projects fail?
Most failures happen due to poor execution like weak AI model training, lack of monitoring and evaluation, and no business alignment. Without proper support, even AI Agents fail to deliver results.
4. How to measure ROI in AI automation?
Track ROI metrics using KPI reporting, cost savings, and improvements in decision-making. Reducing manual work and duplicate actions also shows value.
5. What tools help in AI automation monitoring?
Use tools that track performance, manage API calls, and provide dashboards for KPI reporting. These tools support better monitoring of machine learning systems.





.webp)
.webp)
.webp)

