
.png)

In 2026, the AI stack is infrastructure not an add-on you bolt onto existing systems. For B2B founders and CTOs, that changes how you hire, what you build first, and where technical debt accumulates fastest.
Three years ago, wrapping GPT-4 API calls in a backend counted as "adding AI." That approach holds up for demos but breaks under real load when your largest customer is running month-end close at 2am and your pipeline starts dropping responses.
This guide breaks down the five layers of the modern AI stack: what each layer does, which tools are showing up in production B2B SaaS stacks, and where startups consistently get into trouble.
Why the AI Stack Looks Nothing Like It Did in 2023
In 2023, most teams kept it simple: call an API, get a response, display it in the UI. The problems surfaced fast. Hallucinations with no audit trail. Inference bills that scaled faster than revenue. Models silently patched on the provider side with no versioning on yours.
Teams building production document processing or customer support automation that year learned fast: a standalone API call is a starting point, not a stack.
How the stack changed: 2023 vs 2026, layer by layer
The divide goes deeper than adding more tools. The architecture philosophy changed.
At the data layer, static knowledge bases gave way to real-time ingestion pipelines. At the model layer, teams stopped picking one API and started routing between models based on task complexity. At the application layer, the scope expanded well beyond chatbots into agentic workflows that execute real business logic. And the ops layer, which barely existed in 2023, became non-negotiable: prompt versioning, per-user cost tracing, systematic evaluation pipelines.
A team still running a 2023 setup in 2026 has no prompt versioning, no cost tracing, and no way to know when model behavior shifts.
The 5-layer model explained: how to read this guide
There are five layers to the current AI stack:
(1) Data and infrastructure
(2) Generative AI architecture and pipelines
(3) Developer tooling
(4) Deployment and ModelOps
(5) Observability.
Each has its own failure modes and tradeoffs. Early-stage teams can deprioritize Layer 5 initially. Layers 1 and 4, however, need to be locked down before you handle any sensitive enterprise data. The framework helps you make decisions in sequence not all at once.
How to Choose AI Tools at Each Layer (Before You Touch the Stack)
The most common mistake is not picking the wrong tool it's picking tools without a clear picture of what you actually need. A team gets excited about a new orchestration framework, builds on top of it, and discovers six months later it was the wrong abstraction. That architectural debt doesn't go away on its own.
The 4 questions that eliminate 80% of bad tool choices
What specific problem are you solving? Not "add AI." Specific means: reduce support response time by 60% without adding headcount. That specificity tells you which layers actually need investment.
Real-time or batch? A copilot that drafts emails on behalf of the user needs sub-second latency. A system that analyzes sales call transcripts overnight can afford to be slower and cheaper. These two requirements look completely different at the infrastructure level.
What does failure actually cost? If a bad output causes your customer to lose money, you need evaluation frameworks and human review before anything ships. If it occasionally sends a slightly off marketing email, you can afford to iterate in production.
Own the model or rent it? Most startups should rent OpenAI, Anthropic, Gemini. Building your own makes sense when you have proprietary training data, strict data residency requirements, or enough inference volume that API costs are genuinely hurting your margins.
Layer 1 - Data and AI Infrastructure
Everything else depends on this layer. A weak data foundation means your model is working from stale or incomplete information, and no amount of engineering workarounds fixes that downstream.
AI infrastructure companies and platforms worth knowing in 2026
Vector databases are the default for any retrieval-based system. Pinecone's managed option is what most teams reach for when they want reliability without the operational overhead. Weaviate and Qdrant are solid open-source alternatives if you want more control. Chroma works well for local development and small-scale deployments.
The honest truth: which vector database you choose matters less than how you chunk, embed, and retrieve your data.
For real-time ingestion at high throughput, Confluent and Redpanda are the standard choices. Smaller teams without a dedicated data engineer usually get by with simpler event-driven setups using Inngest or Trigger.dev.
Teams without ML engineers on staff should start with cloud-native systems: AWS Bedrock, GCP Vertex AI, or Azure AI Studio. The abstraction cost is worth it until you identify a specific capability gap those platforms can't address.
Layer 2 - Generative AI Architecture and Pipeline Tools
This is where raw infrastructure becomes intelligent behavior. Two patterns dominate this layer: RAG (Retrieval-Augmented Generation, which pulls relevant chunks from your data at inference time and passes them as context to the model) and agent orchestration. Most production RAG systems eventually need orchestration too but they solve different problems.
RAG vs. orchestration: when start-ups need both
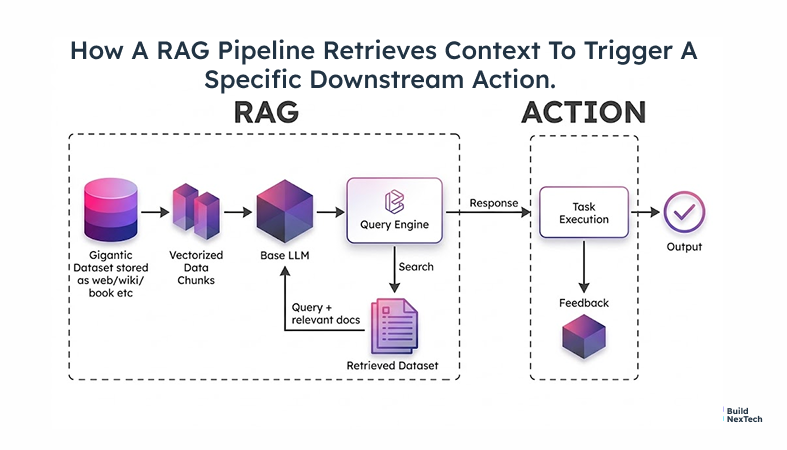
RAG has become the standard for any system that answers questions from proprietary data. At inference time, you pull relevant chunks from your vector store and pass them as context to the model. Outputs get more accurate, easier to trace, and easier to update if you change the data, not the model. LangChain is the most widely deployed framework for this. LlamaIndex tends to be cleaner for document-heavy use cases.
Agent orchestration is a different problem. Agents are multi-step planners they call tools, handle branching logic, and loop until a goal is met. LangGraph handles stateful, cyclical workflows well. CrewAI works for multi-agent setups where different agents own different tasks.
One practical note: don't start with agents. Push RAG as far as it can go first. Agents add latency, cost, and failure modes that are genuinely hard to debug.
Workflow tools startups are standardizing on
Beyond RAG and agents, you need tooling to connect AI logic to the rest of your product. n8n is popular with non-engineering teams. Prefect and Dagster handle complex pipeline orchestration for engineering-heavy systems. Temporal is the choice when you need guaranteed completion across long-running, multi-step processes.
Layer 3 - AI Tools for Product Engineering and Developer Workflows
This is the layer engineers work in every day, and it's seen more tooling change than any other over the past two years.
Open source AI tools most engineering teams start with
LangChain and LlamaIndex are the standard starting points for RAG development. Hugging Face is the default for open-weight and embedding models if you need to fine-tune or self-host a model, that's where it lives. For evaluation, PromptFoo and DeepEval let you build systematic test suites of prompt and model behavior before you ship.
When Should You Choose Open Source AI Over Managed Services?
Use managed services when running something yourself would slow you down which describes most early-stage teams for most of the stack. Move to open self-hosting when API costs become a material burden at your inference volume, when data can't legally leave your systems, or when you've identified a specific gap that open-weight models (Llama 3, Mistral) handle better than proprietary APIs.
Should You Build, Buy, or Compose Your AI Stack?
Build the parts that are core to your product and genuinely differentiated. Buy the infrastructure that would take months to maintain yourself Pinecone, Helicone, Langfuse. Use well-maintained APIs and libraries for the middleware in between.
Your competitive advantage isn't any single component. It's how you've wired them together for your specific application.
Layer 4 - AI Deployment and ModelOps Tools
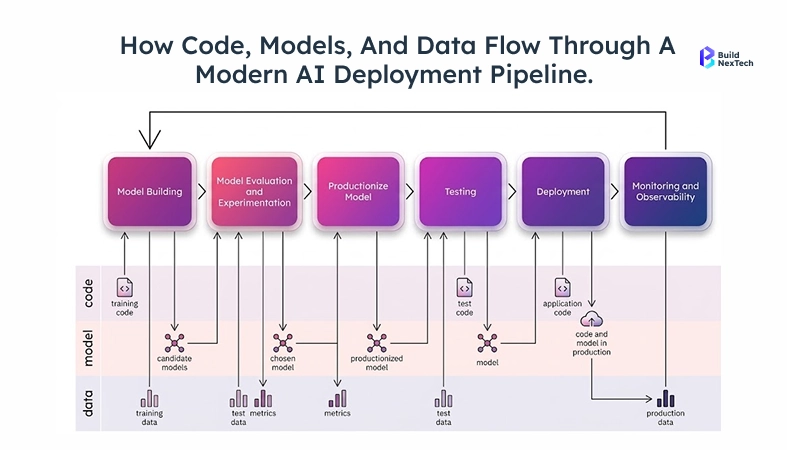
Most teams underestimate the work in ModelOps, which covers versioning, deploying, and monitoring models in production. Getting a model working locally is straightforward. Getting it to perform reliably in production, under real traffic, at predictable cost that's the hard part. Endpoints that return in under 500ms during testing can spike to 4 seconds under concurrent load. Inference costs that work at 100 users can blow up at 10,000.
Why Have AI Agents Become a Default in 2026 Deployment Stacks?
The production agents of 2026 aren't the experimental prototypes from 2023. Teams are running automated research pipelines and multi-step customer workflows with rate limiting, cost caps, guardrails, and human escalation paths built in.
For deployment: containerized inference endpoints on AWS ECS, GCP Cloud Run, or Modal are common. vLLM and Hugging Face TGI handle serving for self-hosted open-weight models.
Teams with reliable CI/CD practices do three things before any model or prompt change goes live: version everything, run shadow deployments, and run automated regression tests against a fixed eval set.
Layer 5 - Observability and Production Reliability
Most startups defer this layer and regret it. The reasoning sounds fine: you're moving fast, you'll add monitoring once things settle. The problem is that AI systems don't fail the way other software does. When a model hallucinates, it doesn't throw an exception. It produces a plausible-sounding wrong answer, passes through your logs clean, and shows up in your churn data three months later.
What Should You Monitor in a Production AI System?
Input drift is under-monitored. When source data changes in format or vocabulary, retrieval quality degrades quietly. Arize AI and WhyLabs track this.
Output quality requires an evaluation baseline. Run your eval suite (PromptFoo, Braintrust) before every prompt or model change, not after.
Cost per request should be on your dashboard from day one. Helicone takes minutes to set up as a proxy and gives you this automatically.
For agent traces understanding which tool calls were made and where reasoning broke down use Langfuse or Arize Phoenix.
Your 2026 AI Stack Won't Build Itself - Start With the Right Layer
Teams that ship reliably don't have the most advanced components. They make good sequencing decisions: they know which layers to build first and which shortcuts are acceptable early on.
The most common failure pattern: teams spend months rebuilding infrastructure that Pinecone, Langfuse, and LangChain already handle well, only to have competitors ship production products while they're still standing up plumbing.
What BNXT.ai handles in your stack - and what it costs to build yourself
Standing up this entire stack from scratch typically takes two to three months of engineering time before you write a single line of product logic based on what we see across B2B SaaS engagements at similar stages. BNXT.ai compresses that by managing the infrastructure layers RAG pipelines, model orchestration, deployment, and monitoring so your team ships product logic from week one instead of spending the first quarter standing up plumbing. Most B2B SaaS teams we work with go from zero to a working RAG pipeline in under two weeks.
That said, this isn't the right fit for every situation. If AI infrastructure itself is your competitive advantage, you need more control than any managed setup can provide. But for most B2B startups, the moat is domain knowledge and product workflow not vector database configuration. If that describes you, talk to the BNXT.ai team most engagements start with a one-week scoping call that maps your stack gaps to a build plan.
People Also Ask

Which AI tools should a startup use in 2026?
Pinecone or Qdrant for vector storage, LangChain or LlamaIndex for RAG, OpenAI or Anthropic for inference, PromptFoo for evaluation, and Langfuse for observability. Add LangGraph or CrewAI only when you genuinely need multi-step agent reasoning.
Do startups really need a full AI stack, or can they just use ChatGPT?
For internal prototypes, consumer AI tools are a reasonable starting point. For customer-facing products at scale, you need access to proprietary data, real-time versioning, evaluation pipelines, and cost control none of which consumer tools provide.
How is an AI stack different from a regular tech stack?
It adds layers traditional stacks don't have: vector storage, model routing, prompt versioning, eval pipelines, and LLM-specific observability. The critical difference is that models degrade silently in ways that uptime monitors and error logs will never catch.
What's the minimum AI stack a startup needs in 2026?
A vector database, a retrieval framework, a managed inference provider, and basic eval tracking. That's a working foundation. Add deployment monitoring before you exit early beta.
Is building an AI stack expensive?
Engineering time is the real cost. API charges are easy to manage at early stages, most seed-stage teams spend under $2,000/month on inference, a rough estimate based on OpenAI's published pricing at 10–50M tokens per month. Building the full stack manually takes months. Using purpose-built infrastructure like BNXT.ai cuts that significantly.





.webp)
.webp)
.webp)

