
.png)

I've spent the last few years building systems that react to things as they happen not after the fact. And somewhere along the way, I realized that most cloud architectures are still stuck waiting. They poll. They batch. They schedule. That worked fine for a lot of use cases, but the moment you wire AI into your infrastructure, the cracks show up fast.
This guide is what I wish I had before I started building event-driven systems at scale practical, honest, and without the usual hand-waving.
Why Event-Driven Automation Is Critical for AI-Native Cloud Systems
Real-Time Processing and Latency Constraints
When you're running AI inference in production, latency is not a soft metric. It's a hard constraint. Whether you're on Google Cloud, Oracle Cloud, or a hybrid cloud setup spanning multiple providers, the gap between an event happening and your system acting on it directly affects outcomes fraud flags, model predictions, user-facing recommendations.
I worked on a system that was using a scheduled Lambda to process payment anomalies every 5 minutes. Sounds fine until you realize that fraud doesn't wait 5 minutes. When we switched to an event-driven architecture with real-time inference, detection latency dropped from ~4 minutes to under 2 seconds. Same model. Different plumbing.
The shift matters because AI-native cloud architectures need feedback loops. If your model outputs a prediction and nothing in the system reacts until the next polling cycle, the prediction is stale. Edge computing vs cloud computing debates often circle this exact problem edge brings compute closer to the event source, but the architecture pattern that enables real-time reaction is event-driven regardless of where you run it.
Why Does Batch-Based Orchestration Break Down for AI Systems?
Batch-based orchestration made sense when storage was expensive and compute was slow. That's not the world we're in. The bigger problem is that batch systems hide failures. A bad record sits in a queue for hours. A failed transformation doesn't surface until the next run. In cloud-native application development, that kind of opacity is expensive.
Kubernetes orchestration can help you scale batch workloads, but it can't solve the fundamental latency problem baked into the architecture. If you're designing a system where decisions need to happen in near real-time pricing, personalisation, anomaly detection batch is the wrong foundation.
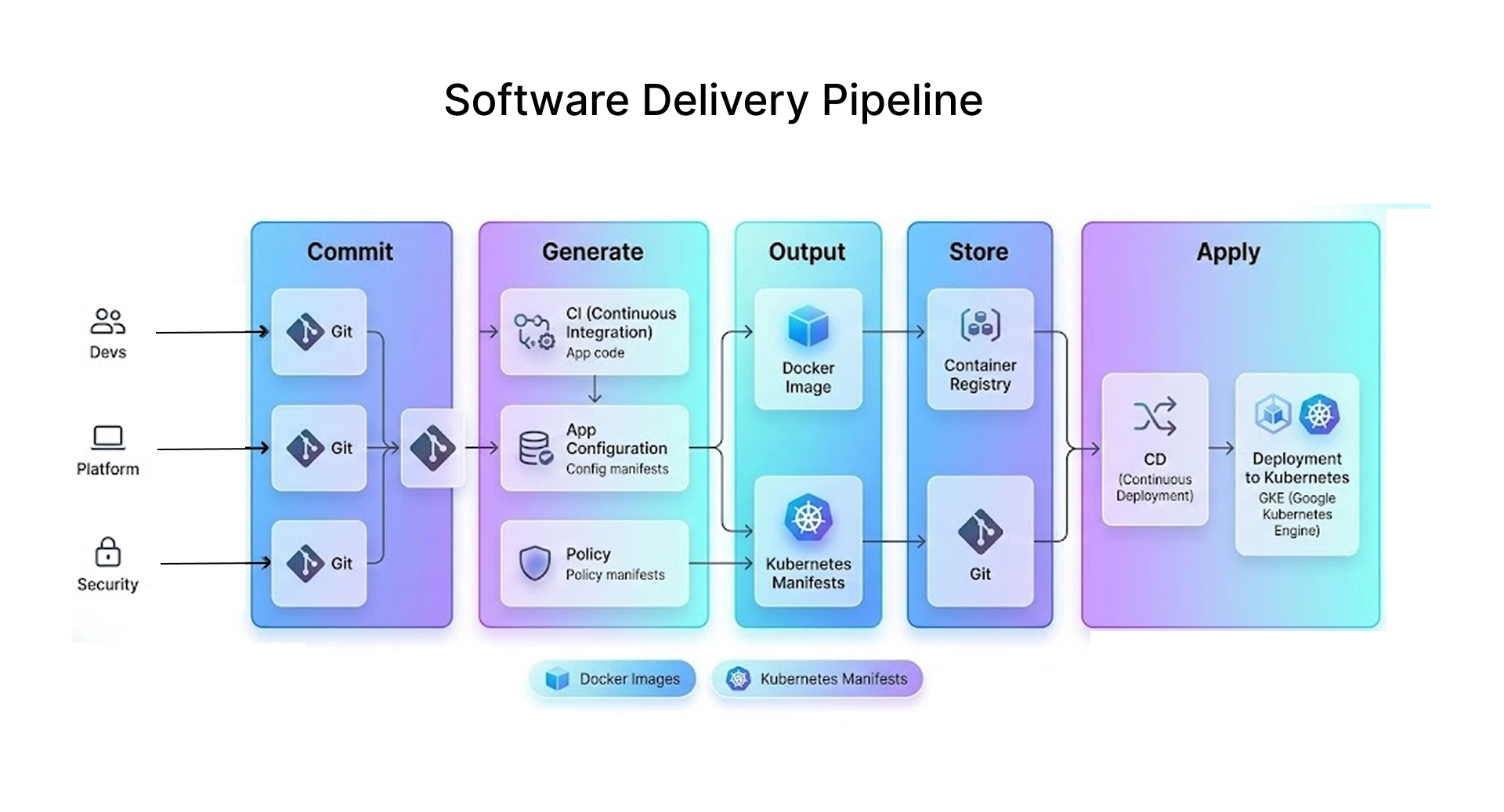
Event-Driven Architecture in Production Environments
Event Contracts, Brokers, and Async Workflows
Here's what I got wrong early: I treated events like function calls. Same payload, same expectations, same timing. That breaks everything once your system gets beyond a handful of services.
In production, events are contracts. They define what happened, not what should happen next. Once I started designing with that in mind using Apache Kafka as my broker and defining strict schemas per event type async workflows became a lot more manageable.
A real example: in a cloud-native application I helped build for a logistics client, we had three consumers reading from the same shipment-status event stream the notification service, the billing engine, and a real-time ML model scoring delivery risk. None of them knew about each other. That's the right way to build it.
This is also where middleware architectures become important. The broker isn't just a queue it's the nervous system. Whether you're using Kafka, AWS EventBridge, or Google Cloud Pub/Sub, the broker determines your throughput ceiling and your replay capability. Get this wrong, and you're rewriting infrastructure at the worst possible time.
How Do You Govern Schemas and Maintain Consistency in Event Pipelines?
Schema drift killed one of our early event pipelines. A downstream team changed a field type from string to integer in their order-created event, and three consumers silently broke. No alerts. Just wrong data accumulating until a human noticed.
Schema registries solve this. Confluent Schema Registry with Avro or Protobuf gives you versioned, enforced contracts. Producers can't publish malformed events. Consumers know exactly what they're getting. In environments with strong cloud security requirements, this also helps with audit trails you, know what data was moved, in what shape, and when.
Governance isn't glamorous. But in event-driven systems, it's what keeps the architecture stable as teams grow.
Observability and Reliability in Event Pipelines
Monitoring, Tracing, and Fault Tolerance
If you can't observe your event pipeline, you don't actually know if it's working. I mean that more literally than it sounds. Events are async. Failures are silent. A consumer that stops processing doesn't throw an exception you'd normally catch it just falls behind.

Tools I rely on: OpenTelemetry for distributed tracing across services, Prometheus for consumer lag metrics, and Grafana for dashboards. On Kubernetes, Kubernetes monitoring through tools like Datadog or Grafana + Loki gives you pod-level visibility into whether your consumers are keeping up with event throughput.
For fault tolerance, the two patterns I use most are dead-letter queues (DLQs) and circuit breakers. DLQs catch events that failed processing without dropping them. Circuit breakers prevent a struggling downstream service from taking down your whole pipeline. Both should be in every production event-driven system — not as afterthoughts, but as first-class design decisions.
One production rule I enforce: every event must have a correlation ID. Tracing a bug across 6 async services without one is a genuinely awful experience.
AI-Driven Automation in Event-Based Systems
Real-Time Inference and Feedback Loops
This is where things get interesting. When you connect AI automation to an event stream, you're not just automating tasks you're creating systems that learn from what's happening right now, not from last week's batch.
A practical setup: Kafka event stream → Flink processor → inference service (say, a FastAPI wrapper around a scikit-learn model) → action event published back to Kafka. The whole loop can close in under 100ms if your infrastructure is sized right.
Here's a code sketch of what that inference microservice might look like:
python
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
app = FastAPI()
model = joblib.load("model.pkl")
class EventPayload(BaseModel):
user_id: str
session_duration: float
page_count: int
cart_value: float
@app.post("/predict")
def predict(payload: EventPayload):
features = [[
payload.session_duration,
payload.page_count,
payload.cart_value
]]
prediction = model.predict(features)[0]
confidence = model.predict_proba(features)[0].max()
return {
"user_id": payload.user_id,
"prediction": int(prediction),
"confidence": round(float(confidence), 3)
}
This gets called by a stream processor each time a user behaviour event arrives. The result gets published as a new event "churn-risk-scored" and downstream services react accordingly: suppress a discount, trigger retention flow, flag for human review.
Risks: Drift, Bias, and Stale Predictions
I'll be direct about this: real-time AI in event pipelines introduces risks that batch inference doesn't. Model drift is the main one. The model you trained on Q3 data might behave unpredictably on Q4 behaviour patterns. In a batch system, you'd notice during the weekly eval run. In a real-time system, you might not notice until a business metric drops.
Stale predictions are a related problem. If your inference service is caching model outputs for performance, you might be serving predictions based on features that no longer reflect the current state. I've seen this cause silent errors in dynamic pricing systems where an old price recommendation persisted in cache while market conditions had shifted.
What helps: shadow mode deployments (run new and old model in parallel, compare outputs before switching), feature drift detection via Evidently AI, and hard expiry on any prediction cache.
Core Architecture Components
Event Streaming, Compute, and AI Pipelines
A production-grade event-driven AI system typically has four layers:
Ingestion layer: Kafka or Kinesis, handling raw event streams from applications, IoT sensors, user actions, or third-party APIs. In a hybrid cloud setup, you might be ingesting from multiple environments into a single broker.
Processing layer: Flink, Spark Streaming, or Kafka Streams for stateful operations windowed aggregations, enrichment joins, deduplication. Kubernetes clusters handle the compute here. Azure Kubernetes Service or Google Kubernetes Engine work well depending on your cloud stack.
AI pipeline: Your inference services, model registries (MLflow), and feature stores (Feast). The Kubernetes dashboard gives you runtime visibility. Cloud native security controls need to be applied here your model endpoints shouldn't be publicly reachable.
Action layer: Where predictions turn into automation. REST calls, database writes, notification dispatches, Terraform cloud-managed infrastructure changes, or downstream event publishing.
Event Flow: From Ingestion to Action
Ingest → Process → Decide → Act
Let me walk through a concrete flow for a fraud detection system on a cloud-native platform:
- Ingest: A payment transaction event lands on a Kafka topic payments.initiated. It contains amount, merchant category, user history hash, and timestamp.
- Process: A Flink job consumes this event, enriches it by joining against a Redis-cached user risk profile, and computes a velocity feature (transactions in last 60 seconds).
- Decide: The enriched event gets sent to the inference service. The model returns a fraud score. If score > 0.85, a payments.flagged event is published.
- Act: A downstream consumer reads payments.flagged and triggers the appropriate automation block the transaction, notify the fraud team, update the user's risk profile for future events.
The whole flow happens in under 500ms. No human in the loop unless the model triggers escalation.
Advanced Use Cases
Anomaly Detection and Auto-Remediation
One of the most useful applications I've seen is coupling Kubernetes monitoring with event-driven auto-remediation. A spike in pod restart events triggers an automated playbook scale the deployment, reroute traffic, create a PagerDuty incident, and publish a diagnostic summary to Slack. No human required for the first 5 minutes of a production incident.
The setup uses Prometheus alerting rules → AlertManager → a webhook consumer → Kubernetes API. Kubernetes security rules ensure the remediation service only has the RBAC permissions it needs, nothing broader.
Dynamic Pricing and Security Intelligence
Dynamic pricing is a clean fit for event-driven AI. Price events come in from market feeds. A model re-scores the optimal price in real time. The updated price gets pushed to the product catalog within seconds. Traditional batch pricing runs once a day real-time event-driven pricing can react to competitor changes, inventory levels, and demand signals as they happen.
On the security side, cloud security solutions built on event streams can detect lateral movement, privilege escalation, and data exfiltration patterns in near real-time. Cloud security services from providers like AWS Security Hub and Azure Defender already emit security events consuming those events through a stream processor and running anomaly detection against them gives you a lightweight SIEM without the full overhead.
System Design Trade-offs
When Should You Choose Consistency Over Latency in Event-Driven Systems?
This is the honest part of the guide. Event-driven systems are eventually consistent by design. If your business logic requires strong consistency "the inventory count must be exactly correct before the order is confirmed" event-driven is the wrong pattern for that specific interaction. Use synchronous calls with distributed locks for those cases.
For everything else, eventual consistency is acceptable and the latency benefits are worth it. The key is being deliberate about where you draw that line rather than discovering it in production.
Scaling vs Cost Control
Kafka clusters on Kubernetes can scale to handle millions of events per second. But that scaling comes with real cost. Cloud services on auto-scaling configurations can rack up unexpected bills fast if you don't set consumption limits and right-size your consumer groups.
At bnxt.ai, we typically recommend starting with a single consumer group per domain, profiling actual throughput under load, and only scaling from there. Over-provisioning event infrastructure is one of the more common mistakes in early-stage implementations.
The cloud storage alternatives question also comes up here do you store every event in object storage for replay, or do you rely on Kafka's retention window? The answer depends on your compliance requirements and replay needs. Cloud seeding your event history into S3-compatible storage is often the right answer for regulated industries.
Best Practices for Implementation
Loosely Coupled Design and Strong Observability
If I had to reduce this entire guide to two rules, these are them.
Loosely coupled design means: producers don't know who's consuming their events. Consumers don't depend on a specific producer being alive. You can deploy, scale, or retire services independently. This is what makes the architecture resilient. The moment you add a synchronous dependency between an event producer and consumer, you've lost most of the benefit.
Strong observability means: every event has a correlation ID, every service emits traces, every consumer reports lag. You want to know at any moment how far behind your consumers are, which events are sitting in the DLQ, and what percentage of your inference calls are returning above a confidence threshold.
Workflow automation tooling like n8n automation or similar workflow automation tools can handle simpler automation chains, but once you need stateful, high-throughput event processing, you need a proper stream processor. Knowing when to reach for n8n versus Flink versus a simple Lambda consumer is genuine engineering judgment and it comes from having hit the limits of each..
Testing is non-trivial. Test automation for event-driven systems means testing not just individual services but the contracts between them consumer-driven contract testing with tools like Pact. It also means testing time-based behaviors, which standard unit tests don't cover.
Conclusion
Event-driven architectures work well when designed deliberately. They're not a silver bullet, and they carry real complexity schema management, distributed tracing, eventual consistency, model drift. But for AI-native cloud systems where real-time decisions matter, they're the right foundation.
The organisations I've seen succeed with this approach share a few things: they invest in observability before they need it, they treat event schemas as public APIs, and they test their failure modes explicitly rather than hoping for the best.
If you're starting from scratch or migrating from batch-based orchestration, the advice I'd give is to start with one domain, instrument everything, and treat the first implementation as the one that teaches you what the second should look like.
At bnxt.ai, we've built event-driven AI pipelines for fraud detection, dynamic pricing, and real-time personalisation across AWS, GCP, and hybrid setups and we know where the traps are.
People Also Ask

How do you choose between event-driven architecture and workflow orchestration in AI systems?
Use event-driven for independent, real-time reactions with no central coordinator. Use orchestration when you need guaranteed step sequencing and retry logic.
What factors should you consider when selecting an event broker for AI-native architectures?
Prioritise throughput, replay capability, and schema registry support. Also check exactly-once delivery semantics if your AI actions aren't idempotent.
How do you manage schema evolution without breaking event consumers?
Use a schema registry with Avro or Protobuf and only make backward-compatible changes. Treat every schema change like a public API change.
When should you use serverless vs containers for event processing?
Serverless fits low-volume, stateless handlers where cold starts are acceptable. Use containers when you need persistent connections or consistent sub-100ms inference latency.
How do you ensure data quality in real-time event streams?
Enforce schema validation at ingestion and flag nulls, duplicates, and out-of-range values in your stream processor. Route bad events to a dead-letter queue instead of dropping them silently.





.webp)
.webp)
.webp)

