
.png)

Nobody gets into QA because they love triaging bugs. You find a defect, log it, spend twenty minutes debating whether it's a P2 or a P3, and then watch it sit in a backlog untouched for two sprints. Do that across a team running hundreds of tests every day, and what starts as a minor inconvenience quietly becomes the thing holding releases back.
AI-powered bug triage won’t fix everything. But for teams dealing with high test volume and slow defect cycles, it removes work that drains engineers without adding much value-especially when integrated with your existing CI/CD pipeline. With the support of AI development services, teams can further streamline triage workflows and improve decision-making. This guide covers what it actually does, what genuinely improves, where it still struggles, and how to implement it without disrupting the QA workflow you already have.
What Is AI-Powered Bug Triage and How It Works
Before jumping to tooling decisions, it's worth being clear about what AI bug triage actually does under the hood. The term gets used loosely - sometimes for simple automation, sometimes for full ML-based classification. Here's what it means in practice across three specific areas.
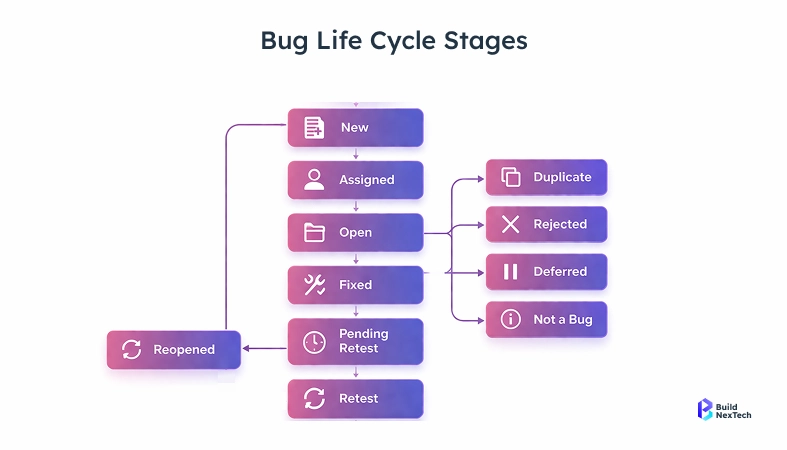
Bug Triage in Software Testing - A Quick Overview
Bug triage is the process of reviewing reported defects, assessing their severity and priority, routing them to the right team, and deciding what gets fixed before the next release. In most QA setups, this is a manual, meeting-heavy process - and it scales poorly.
A typical manual triage cycle looks like this:
- A test suite runs overnight and generates 200+ failure logs
- A QA lead reviews each failure manually the next morning
- Each failure gets classified by severity and priority
- A ticket gets created, filled in, and assigned to a developer
- The developer disputes the priority or reassigns it
- The cycle restarts next sprint
The problem isn't that engineers are bad at triage. It's that triage is repetitive and attention-intensive at scale. Reviewing 300 failed test cases in one sitting is genuinely hard to do consistently. Important bugs get under-prioritized. Flaky failures get escalated. And the people doing it get tired of it fast.
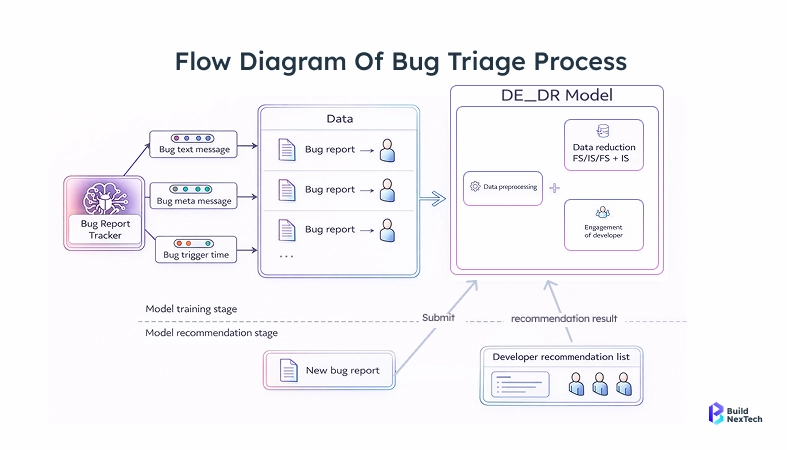
How AI Is Transforming Bug Triage in QA Automation
AI bug triage tools use machine learning models trained on historical defect data to handle the classification, routing, and deduplication - a core capability of AI/ML development services.
What these models actually do:
- Classify severity automatically - learning from past defects using classification algorithms to determine whether a new failure is critical, major, or minor
- Predict ownership - using code change history and module ownership to route tickets to the right engineer without manual assignment
- Flag duplicates early - comparing new failures against open tickets before a second report gets created
- Separate regressions from flaky tests - identifying intermittent failures based on historical pass/fail patterns so they don't get treated as real bugs
- Pull together failure context - stack traces, recent code changes, and related tickets in one place, so the assigned engineer doesn't spend 30 minutes hunting for background
The output isn't a final verdict. It's a reasoned suggestion. Engineers still review and override. But the gap between "test failed" and "triaged, assigned, and in someone's queue" shrinks from hours to minutes.
How Bug Triage Works in Modern CI/CD Pipelines
In a CI/CD setup, triage latency has a direct cost. A pipeline that runs on every commit can't absorb a 48-hour review queue. Bugs found Tuesday afternoon need to be moving toward a fix before Thursday's release - not surfaced in next week's standup.
AI triage plugs in as a step after the test runner. Code is pushed, tests run, the classifier ingests the failure output, and tickets are created automatically with severity, priority, and assignee pre-filled. If the failure matches an existing open ticket, it links rather than duplicates. Developers see it in their board within minutes.
No triage meeting. No overnight queue.
Key Benefits of AI-Powered Bug Triage in QA
The time savings are real, but they're not the whole story. The bigger value is what your team does with the hours they get back. These four benefits compound over months, not just sprints.
Faster Releases with Test Automation and CI/CD Integration
The most direct benefit is speed. When triage is automated, defects don't wait for a human to open a queue. Developers get reports in near-real time. Fixes get assigned the same day failures are detected.
Where the speed improvement shows up most:
- Same-day defect assignment - no overnight wait for the morning review
- Automated ticket creation - no engineer manually filling in fields for 200 failures
- Immediate P1 escalation - critical failures get flagged right away instead of sitting in a queue
- Faster fix cycles - developers can pick up and resolve bugs within the same sprint they were detected
For teams deploying multiple times daily, catching a bug two hours after it appears beats catching it two days later after a customer reports it.
Increased QA Productivity with AI Automation Tools
Manual triage burns QA bandwidth in ways that don't show up in sprint metrics. In high-volume pipelines, failure review commonly consumes two to three hours of QA time daily - time that doesn’t show up in sprint metrics. Engineers blocked on triage aren’t writing test cases, investigating root causes, or improving automation coverage. They’re doing data entry.
What AI triage gives back to QA teams:
- Engineers review suggestions instead of building classifications from scratch
- Duplicate detection removes the manual cross-referencing against existing backlogs
- Context aggregation means developers get what they need in the ticket without QA having to write it all up
- QA leads can focus on strategy and coverage gaps instead of backlog hygiene
The recovered time varies by team size and volume, but for most teams running 200+ daily tests, it’s measurable within the first sprint. That’s time for better tests, not better ticket formatting.
Improved Accuracy in Bug Classification and Prioritization
Here's something manual triage processes rarely acknowledge: two experienced engineers will classify the same failure differently when they're tired or moving fast. Priority inflation is common - marking everything P1 "just to be safe" destroys the signal that priorities are supposed to provide.
AI models apply the same logic to every ticket. No bad days. No sprint pressure affecting the call. Trained on your historical data, they learn what "critical" actually means for your product - not a generic framework that doesn't map to your codebase.
In practice, this means:
- Consistent severity classification across teams and time zones
- Fewer false P1s that bury real priorities in noise
- Tickets that reach the right owner the first time
- Duplicates caught before they clutter the backlog
Worth being honest about the limit here: if your historical triage data was inconsistent, the model learns that inconsistency. Cleaning the training data before model training isn't optional.
Better Collaboration Across QA and DevOps Teams
Automated triage produces uniform ticket data. Every report has the same fields populated, the same format, the same context. That consistency makes the backlog useful for reporting - not just a place bugs go to age.
Collaboration gets easier in a few specific ways:
- Developers get complete context in the ticket - no back-and-forth asking for stack traces
- QA leads can pull reliable metrics without manually auditing ticket quality
- Code-ownership-based routing removes the ambiguity about who handles what
- The model's reasoning is visible - nobody wonders why a bug landed on their team
AI-Powered vs Traditional Bug Triage
Understanding where manual triage breaks down helps you figure out whether AI triage solves your actual problem - or whether something else is the real bottleneck. The comparison is more useful when it's honest about both sides.
Where Does Manual Bug Triage Break Down?
Manual triage doesn't scale. A team of five QA engineers can manage it with discipline and decent tooling. A team running continuous testing across 12 microservices can't. At some point the failure volume simply outpaces human review capacity.
Specific failure modes of manual triage:
- Triage lag - bugs sit unactioned for 24 to 72 hours because the reviewer is in meetings or hasn't opened the queue
- Inconsistent classification - P2 means different things to different engineers on different days
- Priority inflation - engineers mark everything P1 to ensure attention, which destroys prioritization signal entirely
- Backlog debt - untriaged tickets pile up until someone schedules a painful grooming session
- Burnout - triage is draining, repetitive work with low autonomy and high volume
What Are the Concrete Benefits of AI-Powered Bug Triage?
AI triage handles volume without degrading. Whether the pipeline produces 50 failures or 5,000, the classifier runs in the same time window and applies the same logic. It doesn't get tired at 4pm on a Friday or make looser calls when the sprint is ending.
Key advantages over manual triage:
- Scales with test volume without adding headcount
- Applies consistent classification logic to every ticket, every time
- Improves over time as engineers correct suggestions - overrides become training signal
- Runs continuously - failures are triaged immediately, not during business hours only
- Deduplicates automatically without manual cross-referencing
How Do AI Triage and CI/CD Work Together?
AI triage and CI/CD work better together than either does alone. CI/CD provides high-frequency test execution. AI triage provides fast-turnaround defect processing. Together, the cycle from "code change" to "assigned bug report" goes from days to minutes.
That compression compounds: less triage time means more engineering hours available, faster assignment means faster fixes, and faster fixes mean shorter release cycles with more reliable outputs.
Implementing AI-Powered Bug Triage in Your QA Workflow
Most implementations fail not because of the tooling but because of the sequence. Teams pick a tool, skip the assessment, deploy too broadly, get inconsistent results, and conclude that AI triage doesn't work. It usually does - just not without groundwork.
Assess Your Current QA Process and Identify Gaps
Before touching any tooling, map what triage actually looks like today. Not what the process doc says - what actually happens in practice.
Questions worth answering honestly:
- How long does it take from test failure to triaged ticket today?
- Who owns triage, and how many hours per week does it consume?
- How consistent is current classification? Pull 50 random P2 tickets and check if they represent the same severity level.
- How clean is historical defect data? Are severity and priority fields reliably filled in?
- What percentage of failures are flaky? A rule of thumb widely cited in the industry: above roughly 15% flakiness, the noise starts undermining the signal for any classifier. Fix that before deploying AI triage.
This baseline has two jobs: it gives you a measurement anchor for improvement, and it shows where model training data will be weakest.
Choose the Right Tools and Integrate with CI/CD
The tooling options range from test-runner plugins to standalone defect intelligence platforms. The integration that matters most is your issue tracker - if the tool can't write directly to Jira, GitHub Issues, or Linear, the efficiency gain disappears because engineers end up manually transferring suggestions.
What to look for in an AI triage tool:
- Direct issue tracker integration - automatic ticket creation, not export-and-import
- CI/CD plugin or API - slots into the pipeline as a post-test step, not a separate workflow
- Explainable classification - surfaces reasoning alongside the suggestion, not just a label
- Feedback loop - corrections by engineers feed back into the model over time
- Flaky test detection - distinguishes intermittent failures from genuine regressions
An implementation approach that actually works:
- Start with one high-volume service where triage is most painful
- Run in shadow mode for two to four weeks - compare suggestions to what engineers actually decide
- Use that data to tune the model before going live
- Measure triage cycle time over two sprints post-launch
- Expand to other services based on what you learned
Don't try to roll this out everywhere at once. Narrow scope means faster tuning and faster trust-building with the team.
Challenges and Future of AI-Powered Bug Triage
AI triage solves real problems. It also creates new ones worth knowing before you commit to an implementation. Being honest about both sides is the only way to set expectations that actually hold.
What Are the Biggest Challenges in AI Bug Triage Implementation?
Data quality is the most common failure point. Most teams have years of tickets with inconsistent labels, changed severity definitions, and fields that got left blank. The model learns whatever is in the training data - including the mess.
- Set aside three to four weeks before model training specifically for data cleanup
- Write clear, specific definitions for each severity and priority level and enforce them going forward
Transparency determines adoption. Engineers push back on AI-assigned priority when they don't understand the reasoning. A model that outputs "P1" without explanation creates distrust fast.
- Choose tools that show reasoning alongside every classification
- Make corrections easy and visible so engineers see the model improving based on their feedback
Flaky tests corrupt the signal. If your suite has significant intermittent failures, the model will struggle to separate noise from real regressions. This is a test maintenance problem, not an AI problem - but it directly affects triage quality.
- Fix flakiness before deploying AI triage, not after
- Quarantine known flaky tests from the AI pipeline while you stabilize them
Where Is AI-Driven QA Automation Heading?
Based on current vendor roadmaps and early production deployments as of early 2026, AI-driven QA is moving beyond classification toward prediction and remediation. A few directions worth watching:
- Autonomous remediation - some tools already generate fix suggestions for narrow failure categories like accessibility violations and deprecated API calls. Tools like Diffblue Cover for Java are early examples, automatically generating unit tests and suggesting fixes based on code behavior.
- Predictive QA - models that analyze code changes and historical failure patterns to predict which areas will break before tests even run. That flips triage from reactive to preventive.
- LLM-based failure analysis - using language models to explain stack traces in plain English and suggest root causes. Accuracy is uneven today, but it's improving fast.
- Cross-service failure correlation - connecting failures across microservices to identify shared root causes rather than triaging each as a separate bug.
Conclusion: Transform QA with AI-Powered Bug Triage
The goal isn't to replace QA engineers. It's to take the work that scales worst - repetitive, volume-driven defect classification - off their plates so they can spend time on things that actually need judgment.
Deliver Faster Releases with Smarter QA Automation
If triage is your release bottleneck, automating it is a real fix. Bugs get caught and assigned the same day they appear, instead of sitting in triage for multiple sprints. QA teams get their hours back for test strategy, coverage analysis, and root cause investigation.
The teams who get the most out of AI triage aren't the ones with the most sophisticated tooling. They're the ones who cleaned their data first, started small, measured carefully, and expanded from there.
How BNXT Helps You Implement Autonomous Bug Triage at Scale
At BNXT, we work with engineering teams running 300+ daily tests who are scaling test automation and hitting the triage wall - typically teams where QA leads are spending 10+ hours a week on defect classification that a classifier could handle in minutes. We implement AI-powered defect intelligence that connects to your existing CI/CD pipeline and issue tracker - no infrastructure rebuild required.
The process: a QA audit to baseline current triage performance, data preparation, pipeline integration, shadow mode calibration, and a working classifier your team can tune over time. If you're running several hundred tests per day and triage is consuming engineering hours you don't have, let's talk.
People Also Ask

How long does it take to implement autonomous bug triage?
Four to six weeks with clean data and an existing CI/CD pipeline; enterprise rollouts can run three to five months.
Does autonomous bug triage work with Agile and DevOps workflows?
Yes - it works best there, since both methodologies generate the test volume that makes AI triage worthwhile.
What kind of data does autonomous bug triage need to function effectively?
Historical defect records with consistently filled fields; 12 months of clean data outperforms years of inconsistent records.
Can autonomous bug triage handle multiple projects at the same time?
Yes, but a shared base model fine - tuned per service works better than a single cross-project model.
How do I measure the success of autonomous bug triage in my QA process?
Track triage cycle time, classification accuracy, override rate, and duplicate ticket rate over at least 60 days.





.webp)
.webp)
.webp)

