
AI Ops
Your IT infrastructure generates more signals than your team can read. AIOps makes sure the ones that matter never get missed.
Schedule a Technical Scoping Call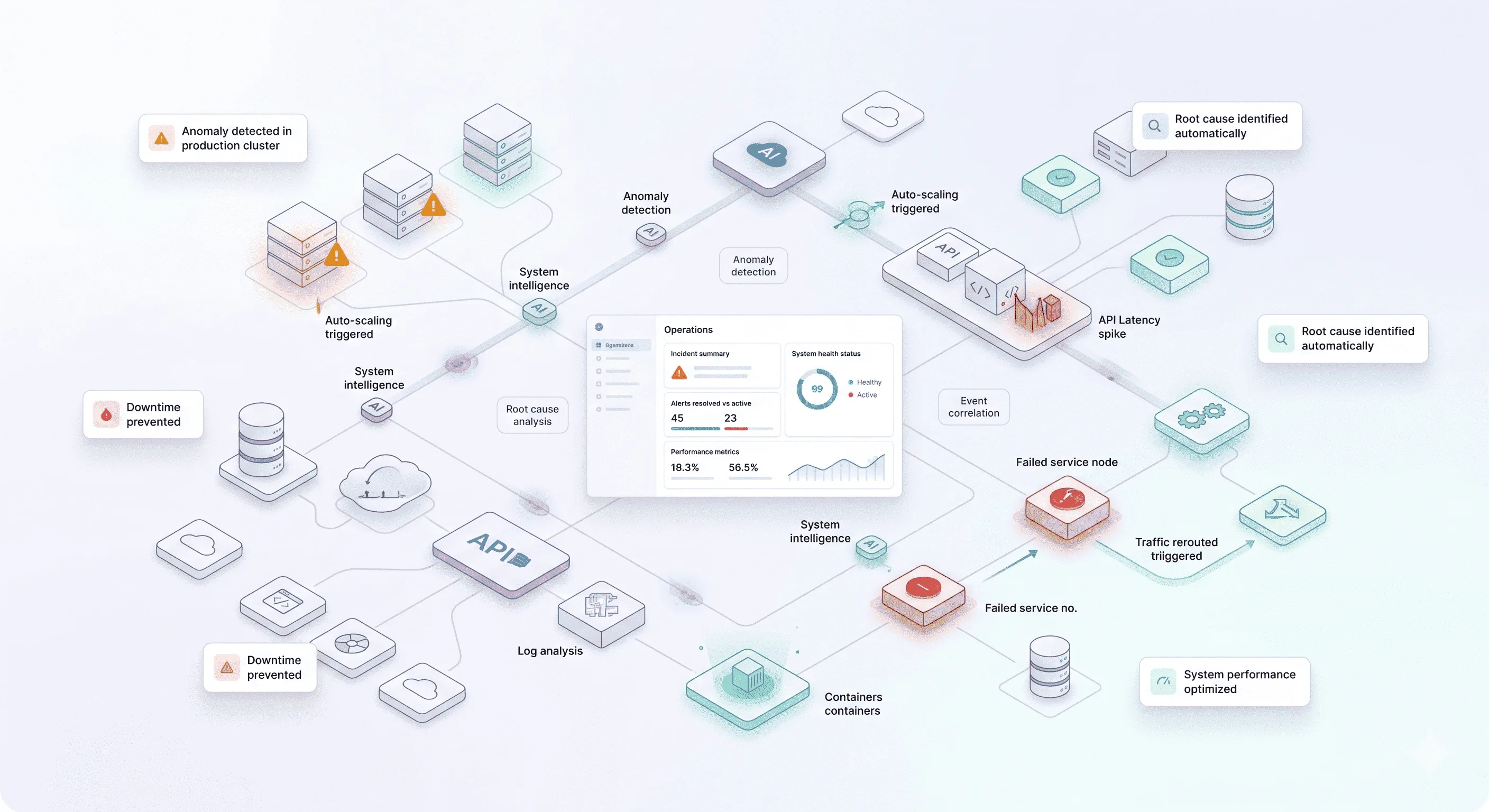
AI Ops
Your IT infrastructure generates more signals than your team can read. AIOps makes sure the ones that matter never get missed.
Schedule a Technical Scoping CallModern IT environments are too complex to manage reactively. A mid-sized enterprise runs hundreds of services, thousands of log events per minute, and monitoring tools that generate more alerts than any team can meaningfully triage. The result is alert fatigue - analysts tuning out noise until something actually breaks, by which point the damage is already in progress.
Incident response compounds the problem. When something does go wrong, engineers spend the first hour correlating alerts across disconnected tools before they can even confirm what's failing. Mean time to resolution stretches. SLAs slip. Business operations stall while the on-call team works through a stack of dashboards that weren't built to talk to each other.
The real cost isn't just downtime. It's the engineering hours burned on low-value triage, the institutional knowledge locked inside senior engineers who know what to look for, and the incidents that were preventable - if anyone had caught the signal early enough.
.webp)
We engineer custom, automated IT operations layers that detect, correlate, predict, and remediate - reducing the gap between signal and resolution to minutes rather than hours.

Log data, metrics, traces, and event streams pulled continuously from across your infrastructure - cloud, on-premise, and hybrid.

ML models group related alerts into single incidents, eliminating duplicate noise and surfacing root cause faster than manual triage.

Anomaly detection identifies infrastructure degradation patterns before they produce outages - flagging risk while there's still time to act.
This requires robust AI Integration to connect across your observability stack, ITSM platform, and cloud infrastructure - often augmented with Autonomous AI Agents to autonomously execute remediation playbooks, gather diagnostic data, and update incident records before an engineer opens the ticket. Explore our AI Services and AI Ops.
We compress incident response times and take preventable outages off the board entirely.

AI Ops system forecasted server failures and optimized auto-scaling, reducing outages by 54% and improving infrastructure reliability across the environment.
A custom AIOps model is built to operate across your full infrastructure surface:
Grouping thousands of raw alerts into a handful of actionable incidents - eliminating the triage queue that burns engineer time on symptoms rather than causes.
Infrastructure degradation patterns identified early enough to schedule remediation during low-traffic windows rather than during incidents.
Automated execution of remediation playbooks for known failure patterns - service restarts, resource reallocation, traffic rerouting - without paging an engineer. See our Self-Healing Framework work.
Every routed incident arrives with correlated context - affected services, probable root cause, historical precedents, and suggested resolution steps - so engineers start solving, not investigating.
Manage dynamic, auto-scaling infrastructure with predictive capacity planning and automated incident response across multi-region deployments.
Maintain pipeline reliability and content delivery SLAs across high-throughput, latency-sensitive environments.
Protect core transaction processing and ledger systems with anomaly detection and automated compliance-aware incident routing.
Consolidate observability across fragmented monitoring tools and reduce mean time to resolution across a large, heterogeneous infrastructure estate.
To build an accurate AIOps layer, we require:
.png)
6–12 months of historical log data, alert records, and incident outcomes with resolution notes and engineer-applied root cause tags.
Integration with your existing observability stack, ITSM platform (ServiceNow, PagerDuty, Jira, or equivalent), and cloud or on-premise infrastructure APIs.
Your AIOps model is fully siloed - your infrastructure data and incident history are never shared or used to train models for other clients.
Off-the-shelf SaaS tools force your data into generic models with escalating per-transaction pricing. BNXT.ai offers
You own the model
and IP.
Trained exclusively on your transaction data, not global averages.
Sits natively inside your existing CRM and LOS - no clunky third-party dashboards.

The model learns the relationship patterns between alerts generated by your specific infrastructure - grouping alerts that consistently co-occur around the same underlying failure into single correlated incidents. Over time, it also learns which alert combinations are false positives in your environment and suppresses them automatically, reducing the volume that reaches your on-call team without suppressing genuine signals.
Yes. We engineer API connections to your existing observability platforms and ITSM systems - Datadog, Splunk, PagerDuty, ServiceNow, and equivalents - so the AIOps layer augments your current toolchain rather than replacing it. Engineers continue working in familiar interfaces; the model operates underneath.
A custom AIOps deployment typically takes 8 to 12 weeks from data ingestion to live integration, depending on infrastructure complexity, the number of monitoring sources being connected, and the maturity of existing incident data available for model training.
Self-healing automation executes predefined remediation playbooks - service restarts, cache flushes, traffic rerouting - for failure patterns where the correct response is well understood and the risk of automated action is low. Higher-risk or ambiguous incidents always route to a human engineer. The scope of automated remediation is defined and approved by your team before deployment.
Every incident that reaches resolution - whether automated or engineer-handled - generates a labeled outcome that feeds back into the model. Correct correlations are reinforced, missed signals are incorporated, and false-positive patterns are suppressed. The system gets more accurate the longer it runs in your environment.

.webp)
.webp)
.webp)

BuildNexTech empowers businesses with expert web development, app development, and cloud migration services.

