
AI Security
Documents don't slow businesses down. Manual handling of documents does.
Schedule a Technical Scoping Call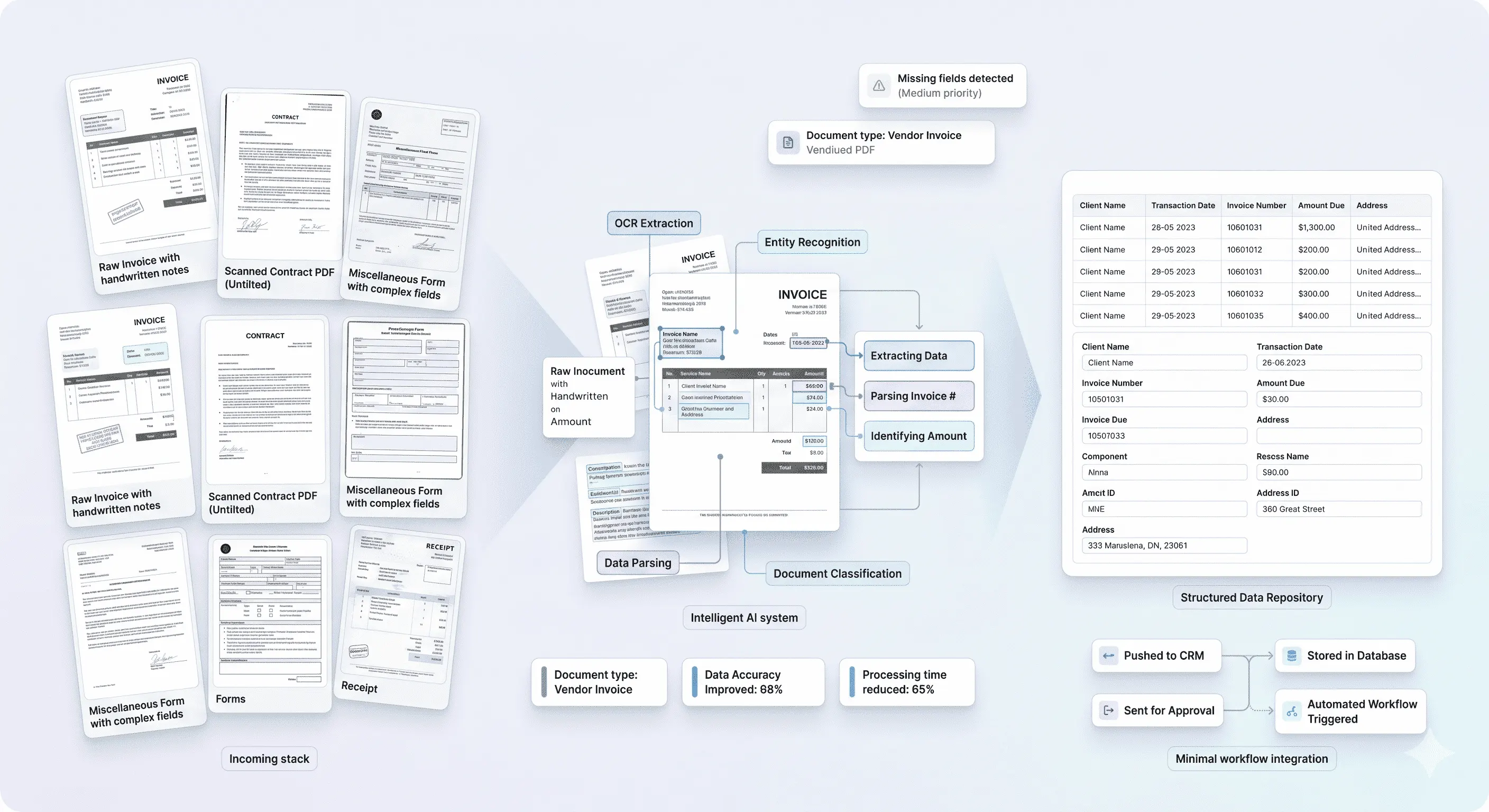
AI Security
Documents don't slow businesses down. Manual handling of documents does.
Schedule a Technical Scoping CallMost organizations process a significant portion of their critical business operations through documents - contracts, invoices, claims, KYC submissions, compliance filings, and loan applications. And most still handle them the same way: a person opens the file, reads it, extracts what matters, and enters it somewhere else.
That model doesn't scale. Document volumes grow faster than headcount. Errors compound across the extraction, classification, and data entry steps. Turnaround times stretch from hours into days. Compliance teams chase audit trails across email threads and shared drives. And the people doing this work are spending their judgment on tasks that shouldn't require it.
The real cost isn't just processing time. It's the decisions delayed, the deals slowed, and the risk exposure that builds when documents sit unreviewed in a queue.
.webp)
We engineer custom, automated document pipelines that extract, classify, validate, and route - operating across every document type in your business without manual intervention.

Documents received across any channel - email, portal upload, API feed, or scanned batch - are captured and queued automatically.

AI identifies document type, structure, and routing category in milliseconds, regardless of format or layout variation.

Key fields, clauses, entities, and data points are pulled with high accuracy using models trained on your specific document library.
This requires robust AI Integration and AI Security to connect document pipelines to legacy infrastructure - often augmented with Agentic AI to autonomously cross-reference external data sources, verify identity documents, or trigger downstream workflows before a human reviewer opens the file. Explore our AI Services.
We eliminate processing backlogs and reduce turnaround from days to hours.

Claim processing time cut from 48 hours to 6 hours with secure AI-based document verification and automated data extraction.
A custom model is trained to handle the full range of documents your business runs on:
Clause extraction, obligation identification, expiry tracking, and deviation flagging against standard templates automated before a lawyer opens the file. See how we built a Legal-Domain LLM for Contract Interpretation.
Automated extraction of key metrics, disclosures, and comparative figures from earnings reports and regulatory filings. See how we built a Custom Financial LLM for Equity Research.
Extraction of diagnoses, medications, and treatment histories from clinical notes and referral documents for downstream reporting workflows. See our Healthcare LLM for Clinical Knowledge Retrieval.
Automated verification of passports, licences, utility bills, and incorporation documents against onboarding rules and compliance thresholds.
Extract and validate claims documents before adjudication, reducing manual review cycles and accelerating payout timelines.
Automate contract review, case file classification, and obligation tracking across high-volume document repositories.
Process referral documents, clinical records, and insurance submissions through structured extraction and compliance validation pipelines.
Automate bill of lading, customs documentation, and proof-of-delivery processing across high-throughput operations.
To build an accurate document processing layer, we require:
.png)
A representative sample of your document types minimum 500–1,000 labeled documents per category for extraction model training.
API access to your document intake channels (email server, upload portal, or scanner network) and target systems (CRM, ERP, DMS, or core platform).
All documents are encrypted at rest and in transit. Your processing models are fully siloed your documents and extracted data are never shared or used to train models for other clients.
Off-the-shelf SaaS tools force your data into generic models with escalating per-transaction pricing. BNXT.ai offers
You own the model
and IP.
Trained exclusively on your transaction data, not global averages.
Sits natively inside your existing CRM and LOS - no clunky third-party dashboards.

The model combines layout analysis, named entity recognition, and contextual understanding to locate and extract fields - even when documents have inconsistent formatting, handwritten sections, or free-form text. It is trained on your specific document types, so it learns the patterns that matter for your workflows rather than applying generic rules.
Yes. We integrate OCR preprocessing into the pipeline to convert scanned images and handwritten inputs into machine-readable text before extraction models are applied. Accuracy on handwritten documents depends on legibility and volume of training samples.
A custom document processing pipeline typically takes 8 to 12 weeks from data ingestion to live system integration, depending on document type complexity, the number of extraction fields required, and the integration surface of your target systems.
The model is trained on pattern recognition, not exact template matching. Novel layouts that fall within the distribution of training data are handled confidently. Documents outside the model's confidence threshold are flagged and routed to a human reviewer rather than processed incorrectly.
Yes. We engineer API connections to standard DMS platforms as well as legacy document storage infrastructure - so processed data lands where your teams already work, without requiring a parallel system or manual transfer step.

.webp)
.webp)
.webp)

BuildNexTech empowers businesses with expert web development, app development, and cloud migration services.

